데이터를 분석하고 머신 러닝/딥러닝 모델을 학습할 때, 많은 연구자들이 활용하고 검증한 공인된 데이터 셋을 활용하는 상황이 가장 이상적이지만, 말 그대로 이상적인 경우에 가깝기 때문에 분석/모델링 도메인에 따라서 필요한 데이터 셋을 직접 수집해야하는 경우가 있다.
웹페이지 크롤링은 수많은 방법 중 하나로 본래 목적은 방대한 정보를 제공하는 서비스(e.g. 검색 엔진)들이 데이터를 최신 상태로 유지하기 위해 사용되었으나 뉴스 분석, 추천 시스템 등의 많은 양의 텍스트 데이터가 필요한 자연어 처리 영역에서도 사용된다.
크롤링을 쉽게 할 수 있는 많은 파이썬 기반 오픈소스 라이브러리들이 있다. 그 중 Selenium과 Beutifulsoup4을 활용한 웹페이지 크롤링 환경을 구축한다.
웹페이지 크롤링에서 Selenium과 Beutifulsoup4의 역할은 아래와 같다.

설치 과정은 간단하다.
1. conda 가상 환경 활성화 (지난 포스팅 참조. Mac OS 카탈리나(Catalina), 콘다(Conda)를 활용한 텐서플로우(tensorflow), 겐심(gensim) 라이브러리 환경 구축)
- conda activate venv

2. Selenium & BeatifulSoup4 설치
- conda install selenium
- conda install


명령어를 입력하고 (y/n)을 물으면 y를 입력하면 완료
3. 크롬 버전 확인 및 크롬 웹 드라이버 다운로드
크롬 브라우저로 크롤링 할 경우 현재 크롬 브라우저의 버전을 확인한다.

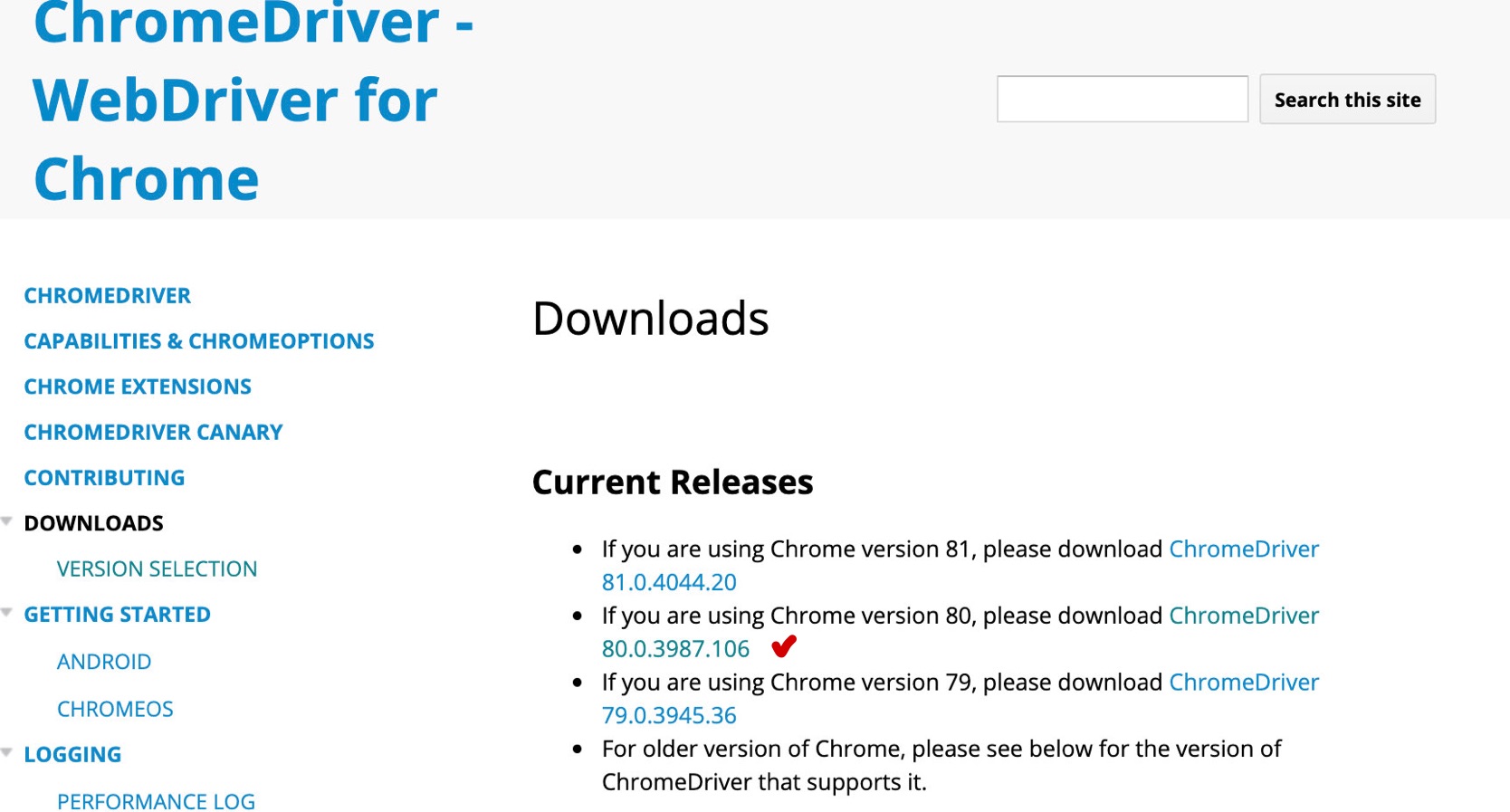
4. 크롬 웹 드라이버 다운로드
크롬 브라우저와 동일한 버전의 웹 드라이버를 다운로드 한다. (아래 그림이 링크를 클릭 후, chromedriver_mac64.zip을 다운로드 한다.)
5. jupyter notebook을 활용한 간단한 예제
jupyter notebook 설치 및 실행 (지난 포스팅 참조. Mac OS 카탈리나(Catalina), 아나콘다(Anaconda-2019.10) 설치)S 카탈리나(Catal
다운로드한 크롬 웹 드라이버를 (jupyter notebook의) notebook 파일과 동일한 경로에 있는 경우, 아래 그림과 같이 경로를 입력해주면 된다. 그렇지 않은 경우, 크롬 웹 드라이버가 있는 파일 경로를 입력해준다.

다음, Conda를 활용한 Tensorflow와 gensim 라이브러리 설치
Mac OS 카탈리나(Catalina), 콘다(Conda)를 활용한 텐서플로우(tensorflow), 겐심(gensim) 라이브러리 환경 구축
이전에 Anaconda3을 설치하고 오늘은 Tensorflow, Keras , Gensim 라이브러리 환경을 구축한다. tensorflow2 부터 패키지 이름으로 CPU와 GPU를 구분하지 않는다. Mac의 경우엔 패키지 이름으로 CPU와 GPU를 구분..
106100109116.tistory.com
다음, Selenium과 BeautifulSoup을 활용한 네이버 인기 급상승 검색어 크롤링 및 시각화(matplotlib, wordcloud)
Selenium과 BeautifulSoup을 활용한 네이버 인기 급상승 검색어 크롤링 및 시각화(matplotlib, wordcloud)
지난 포스팅에서 웹 크롤링을 위해 selenium과 BeutifulSoup을 설치했다. 이번엔 실제로 웹 크롤링을 간단하게 해보고 그 데이터를 시각화해 볼 것이다. 데이터를 분석할 때 통계 기술들을 활용하여 표본 데이터로..
106100109116.tistory.com



댓글