지난 포스팅에서 웹 크롤링을 위해 selenium과 BeautifulSoup을 설치했다. 이번엔 실제로 웹 크롤링을 간단하게 해보고 그 데이터를 시각화해 볼 것이다. 데이터를 분석할 때 통계 기술들을 활용하여 표본 데이터로 더 큰 규모의 데이터 패턴을 추측하기도 하고, 잘 알려진 비지도 모델을 활용해 데이터의 패턴을 찾기도 한다.
위와 같은 방법도 좋지만 데이터를 시각화해보는 것 역시 가치있는 정보를 제공해 줄 가능성이 있으며, 무엇보다 가시적인 결과는 전달하는 바가 명확하다. 오늘은 간단히 네이버에서 인기 검색어를 수집하고 그 빈도를 시각화 해볼 것이다.
1. 네이버 웹 페이지
네이버 메인 페이지의 급상승 검색어를 클릭하면 클릭 시점 기준으로 1위부터 20위까지 인기 검색어를 볼 수 있다. 메인 페이지에서는 현재 시점 기준의 급상승 검색어만 나오기 때문에 조금 더 자세히 살펴보기위해 우측 하단의 DataLab을 클릭한다.
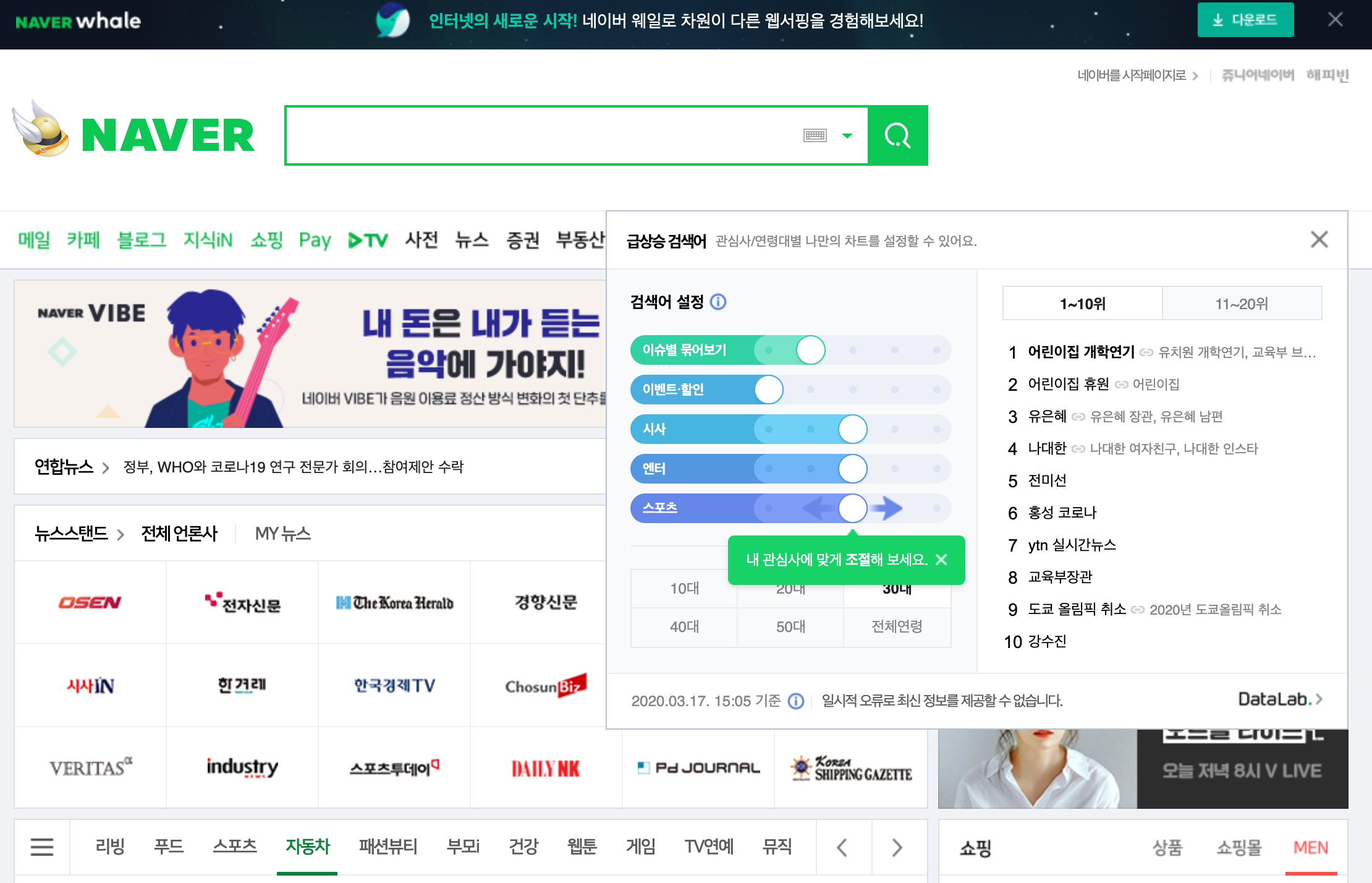
이 페이지에서는 메인 페이지와 달리 특정 시기, 연령대, 카테고리 등 추가옵션과 함께 급상승 검색어를 탐색할 수 있다.

집계 주기의 날짜와 시간과 연령대를 바꿔서 검색해보면 브라우저 상단에서 다음과 같은 URL을 얻을 수 있다.

이제 selenium으로 이 url을 활용해서 2020년 1월부터 3월사이 밤 10시, 10대~30대 연령대별 인기 검색어 정보를 수집해볼 것이다.
2. selenium과 beutifulsoup을 활용한 웹 페이지 크롤링
먼저 사용한 라이브러리를 다음과 같다.
from selenium import webdriver # 웹 페이지 크롤링을 위해 사용
import bs4 #beutifulsoup # 수진한 웹 페이지를 파싱(parsing)하고 text데이터만 읽기 위해 사용
import collections # 검색어의 검색 빈도를 계산하기 위해 사용
import time # 과도한 트래픽 유발을 피하기 위해서 sleep() 함수를 사용하기 위해 사용
import calendar # 날짜 계산의 편의를 위해 사용
import matplotlib.pyplot as plt # 간단한 그래프를 그려보기 위해 사용
from matplotlib import rc # 그래프에 한글 깨짐을 피하기 위해 폰트를 지정하기 위해 사용
from wordcloud import WordCloud, STOPWORDS # wordcloud로 표현하기 위해 사용
import os # 이미지 파일의 경로를 읽기 위해 사용
from PIL import Image # 이미지 파일을 로드하기 위해 사용
import numpy as np # 이미지 파일을 배열로 저장하기 위해 사용selenium으로 웹 페이지를 크롤링하는 코드는 아래와 같다.
dr = webdriver.Chome("./chromedirver") # 지난 포스팅에서 다운로드한 크롬 드라이버의 경로
for i in range(1, 4): # 1월부터 4월
for j in range(1, claendar.mathrange(2020, i)[1]+1): #각 달의 날짜 범위
if i == 3 and j > 16:
break
url="https://datalab.naver.com/keyword/realtimeList.naver?
\age=%ds&datetime=2020-%02d-%02d"% (40, i ,j) # 연령대와 날짜
url=url+"T%02d:%02d:00&where=main#" % (22, 0) # 시간대
dr.get(url)
### beatifulsoup 코드 추가 필요 ###
time.sleep(5)
dr.close()위 코드를 실행하면 크롭 웹 드라이버가 켜지고, 페이지가 변경되는 것을 확인 할 수 있다. 각 페이지에서 수집한 데이터는 dr.page_source에 저장되어 있다. 이 웹 페이지에서 원하는 검색어 정보만을 읽기 위해 beautifulsoup 모듈을 사용해야 하는데, 그 코드는 아래와 같다.
dr = webdriver.Chome("./chromedirver") # 지난 포스팅에서 다운로드한 크롬 드라이버의 경로
rawtext=[]
for i in range(1, 4): # 1월부터 4월
for j in range(1, claendar.mathrange(2020, i)[1]+1): #각 달의 날짜 범위
### selenium 코드 추가 필요 ###
rawdata=bs4.BeautifulSoup(dr.page_source,'html.parser')
# beatuilfulsoup을 사용해 웹 페이지의 raw data를 파싱
rawtext.append(rawdata.select("#content > div > div.selection_area > \
div.selection_content > div.field_list > div > div > ul > li"))
# 급상승 검색어 정보를 저장하고 있는 경로에 저장된 텍스트를 select로 탐색 및 저장
time.sleep(5)
dr.close()
rawtext위 코드는 beautifulsoup으로 웹 드라이버로 읽은 데이터를 파싱하고. select()는 웹 페이지의 HTML 구조 내에서 해당 구조를 동일하게 갖는 모든 하위 코드(데이터)를 탐색해주는 메소드로 위 메소드에 전달된 인자는 네이버 데이터랩의 인기 급상승 검색어가 저장된 경로를 의미한다. 이 경로를 가져오는 방법은 다음과 같다.
3. 크롬 브라우저에서 CSS selector를 활용해 원하는 데이터 경로 복사
아래 그림에서 한사랑 요양병원을 한번 클릭한 후, 마우스 오른쪽을 눌러주면 다음과 같은 메뉴가 뜬다. 이 메뉴 중 검사를 클릭한다.
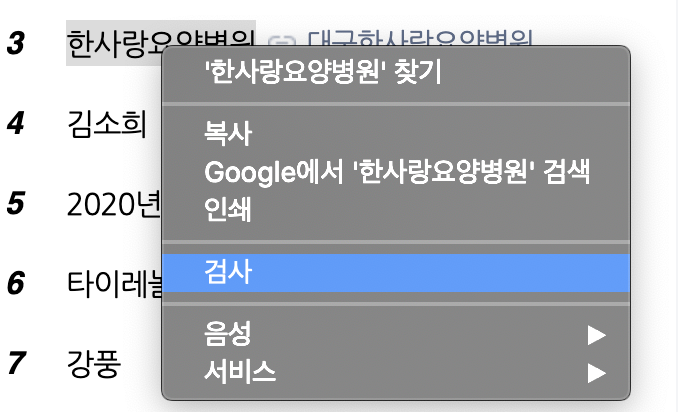

위 HTML코드를 보면 공통된 형식을 볼수 있다.
그림 상단에 <ul class="ranking_list">가 있고 그 하위 클래스로 <li class="ranking_item">...</li>가 반복되는 것을 볼 수 있다. 그중 3번째 <li ~~~ ></li> 가 펼쳐져 있는데 그 하위 내용을 보면 위에 있는 그림에서 검사를 클릭한 문자열이 저장되어 있다. 이를 통해 <ul class="ranking_list"> 하위에 동일한 포맷으로 저장된 데이터들이 검색어 리스트임을 알 수 있으며 위 코드에서 select() 메소드로 동일한 경로를 읽어 검색어 데이터를 가져오는 것이다. 이 경로를 복사하기 위해 CSS selector를 사용하며 방법은 아래와 같다.

위 그림과 같이 코드를 지정하고 마우스 오른쪽을 클릭하여 'Copy > Copy selector' 를 클릭한다. 그 다음 jupyter notebook (또는 다른 코딩 툴)에 붙여넣기하면된다. 이때 일부 태그에 :nth-child(#)가 붙어있을 수 있다. 위 그림에선 :nth-child(3)이 있을 것이다. 리스트내에서 특정 값을 지정하는 경우 함께 카피되는 값으로 이번 크롤링의 목적은 특정 순위의 검색어가 아니므로 삭제해준다.

위 코드를 실행하고 저장된 값을 출력하면 위와 같이 출력될 것이다. 필요한 데이터는 <span class="itme_title">뺑반</span>에 있는 단어 '뺑반'이기때문에 이 데이터만 다시 읽어오도록 한다.
4. 검색어 데이터만 추출
words=[]
for i in rawtext:
for j in i:
text=j.find("span", class_="item_title").text.strip()
words.append(text)
words위 코드는 <span 태그안에 class 이름이 "item_title"인 객체에 저장된 text를 반환하는 find() 메소드로 이 메소드를 수행한 결과를 출력하면 아래와 같이 검색어만 리스트에 담기는 것을 확인할 수 있다.

이제 2020년 1월부터 3월까지 저녁 10시의 급상승 검색어를 모두 수집했기 때문에 간단한 코드로도 가장 빈도수가 높았던 단어를 찾아 볼수 있다.
collections.Counter(words).most_common(10) #가장 빈도수가 높은 10개 검색어
5. matplotlib 라이브러리로 barh 그래프로 시각화
matplotlib모듈이 설치되지 않았다면 conda install matplotlib 또는 pip install matplotlib 명령어를 입력해 설치해준다.
위에서 출력한 빈도수가 높은 10개 검색어 출력 결과를 보면 collections.counter() 메소드 출력 결과가 검색어와 빈도수로 매치되어있는것 볼 수 있다. 그래프로 그리기 위해 두개의 리스트로 분리해준다.
word=[]
freq=[]
word2=words.split(' ') #공백을 포함한 검색어의 경우 공백을 기준으로 분리하여 각 단어로 취급
for w, f in collections.Counter(words2).most_common(10):
word.append(w)
word.append(f)한글을 단어 또는 문장으로 토큰화(tokenizing)해주는 코엔엘파이의 kkma 모듈(konlpy.tag.kkma)과 같이 잘알려진 라이브러리 도구들이 있지만, 현재 데이터는 검색어이기 때문에 공백으로 구분해주었다. 공백으로 구분하지않고 검색어 그자체를 사용해도 의미있는 빈도수를 볼 수 있다.
matplotlib 라이브러리로 barh 그래프를 그리는 코드는 아래와 같다.
rc('font', family = 'AppleGothic') # apple의 경우 2020-03-19 기준 사용 가능,
# window나 linux에서 한글이 깨지는 경우 별도 글꼴 탐색 필요
index = np.flip(np.arange(len(word)))
plt.figure(figsize=(8,20))
plt.barh(index, freq)
plt.title("word vs freq")
plt.xlabel("freq")
plt.ylabel("word")
plt.yticks(index, word)
plt.show()첫 번째 코드는 matplotlib로 그래프를 그리면 한글이 깨지는 경우가 있는데, 이경우 위 코드를 추가해주면 된다. 다른 코드는 특별히 더 설명할 부분이 없을 것 같다.
위 코드를 10, 20, 30 대별 실행한 결과는 다음과 같다.

위 그래프를 보면 연초인 만큼 '나이'의 빈도수가 높고, 최근 세계적 이슈인 '코로나','확진자'등이 상위권에 랭크되어 있으며, 공통된 검색어외에도 10대에는 '아는 형님', 30대에는 '미스터트롯'이 상위권에 랭크되어 있는 것을 볼 수 있다. 이렇듯 시각화만으로도 데이터의 경향을 판단할때 유의미한 패턴을 찾아 볼 수 있음을 확인했다.
위 그래프도 재미있는 고민들을 해볼 수 있지만 조금 더 시각적인 효과를 강조하기 위해 wordcloud로 시각화를 해보자.
6.wordcloud로 시각화
먼저 wordcloud 라이브러리를 설치해야한다. 명령어는 다음과 같다.

'-c conda-forge'는 기본 default 저장소외에 'conda-forge'라는 다른 저장소 채널을 선택해서 다운로드한다는 의미이다.
이 wordcloud는 하나의 문자열에서 내부적으로 토큰화(Tokenizing)를 하기때문에 위에서 구분했던 단어 리스트를 하나의 문장으로 합쳐준다. 코드는 아래와 같다.
tostring=""
for w in words:
tostring=tostring+" "+str(w) #단어들을 하나의 긴 문자열로 변경하되, 단어 사이에 공백을 넣어줌이제 이 긴 문자열을 인자로 WordCloud() 메소드를 호출하여 시각화한다. 코드는 아래와 같다.
d=os.getcwd() #wordcloud에 틀(mask)로 사용될 그림 파일을
#같은 경로에 저장했기 때문에 디렉토리명을 가져옴
mask = np.array(Image.open(os.path.joun(d, 'korea.jpg')))
#이미지 파일을 로드하여 배열형태로 저장
wordcloud = WordCloud(font_path = "/System/Library/Fonts/Supplemental/AppleGothic.ttf"
,background_color='white', mask=mask).generate(tostring)
plt.figure(figsize=(48,48))
plt.imshow(wordcloud, interpolation ="bilinear")
plt.axis("off")각 단어의 빈도수를 정확히 알 수 없지만, 상대적인 빈도수를 반영해서 단어의 크기가 결정되기 때문에 시각적으로 공통으로 빈도수가 높은 검색어와 연령대별 차이를 쉽게 찾아볼 수 있다. 시각화한 결과는 아래와 같다.

이전, Mac OS 카탈리나(Catalina), 콘다(Conda)를 활용한 웹페이지 크롤링 환경 구축(Selenium, BeautifulSoup)
Mac OS 카탈리나(Catalina), 콘다(Conda)를 활용한 웹페이지 크롤링 환경 구축(Selenium, BeautifulSoup)
데이터를 분석하고 머신 러닝/딥러닝 모델을 학습할 때, 많은 연구자들이 활용하고 검증한 공인된 데이터 셋을 활용하는 상황이 가장 이상적이지만, 말 그대로 이상적인 경우에 가깝기 때문에 분석/모델링 도메인..
106100109116.tistory.com



댓글